AI-Ready Finance Data: Why Finance AI Projects Fail on Structure, Not on Models
In finance, weak retrieval, fragile document automation, and low trust usually start long before model choice. The real bottleneck is structure, metadata, validation, and traceability.

In this Article
- The Failure Usually Starts Before the Model
- Retrieval Quality Is a Data-Design Problem
- Document AI Is Structured ETL for PDFs
- Finance Raises the Standard for AI-Ready Systems
- What AI-Ready Does Not Mean
- XRechnung Shows What Good Structure Looks Like
- A Practical Standard for AI-Ready Finance Data
Executive Summary
- Most finance AI projects fail less because the model is weak and more because the source layer was never prepared for retrieval, validation, and auditability
- In document-heavy workflows, chunking, segmentation, metadata, and field logic are not implementation details; they are the effective data model of the AI system
- Document AI only becomes operationally useful when extracted fields are validated, mapped, and traceable instead of stopping at OCR output or loose JSON
- In finance, AI-ready must mean more than machine-readable text; it must include validation rules, lineage, reviewability, and reproducible transformations
- European e-invoicing standards such as EN 16931 and XRechnung offer a concrete example of what structured, downstream-usable finance data looks like
The Failure Usually Starts Before the Model
Most teams still talk about AI projects as if model choice were the decisive question: should we use a larger model, add RAG, switch vendors, or wrap everything in an agent layer?
In finance, those questions often arrive too late.
The real failure point usually appears earlier, at the document and data layer. A human can still read around a messy PDF, infer missing context from a finance export, or mentally reconstruct a broken invoice table. An AI system usually cannot. If a corpus contains unstable headings, weak OCR, inconsistent field naming, mixed layouts, missing metadata, and no reliable segmentation, the downstream result is predictable: weak retrieval, brittle automation, manual cleanup, and low trust in the output.
This is not just a tooling problem. It is increasingly a governance problem. Supervisory and banking-focused sources keep returning to the same pressure points: data quality, traceability, lineage, and auditability. The BIS treats data usage, data quality, and governance as core issues for AI adoption in financial services, while the EBA frames trustworthy advanced analytics around data management, governance, and elements of trust such as traceability and auditability. BIS EBA final report
One concrete example makes the failure mode obvious.
Imagine a team building a retrieval layer over mixed supplier invoices, scanned statements, and ERP exports. Supplier names appear in multiple formats. Some PDFs have poor OCR. Tax amounts are readable, but not always aligned with line items. Dates are captured in inconsistent fields. The system can still embed the text and answer questions. But when asked which invoices qualify for a specific tax treatment, it starts returning plausible fragments without stable source attribution. The problem is not that the model is too small. The problem is that the source layer is structurally unstable.
Retrieval Quality Is a Data-Design Problem
RAG is often described as a model pattern. In practice, it is a data-architecture pattern.
Once a workflow becomes retrieval-driven, chunking and metadata stop being secondary concerns. They become the mechanism through which the system understands the source material at all. A document split at arbitrary token windows may remain technically searchable, but it becomes semantically unstable. Headings get detached from the paragraphs they govern, tables lose business context, compliance clauses are split across chunks, and retrieval starts surfacing fragments that are lexically related to the query but operationally weak.
This is why official guidance and retrieval research keep emphasizing structure-aware segmentation. Microsoft’s Azure AI Search documentation explicitly recommends chunking by document structure and layout when possible, because semantically coherent chunks improve relevance in downstream retrieval. Anthropic’s work on contextual retrieval pushes the same point from another angle: retrieval quality depends not only on embedding and ranking, but also on how much local and document-level context each chunk carries. Azure chunking Azure semantic chunking Anthropic
In finance, this matters more than in generic knowledge search. The real questions are often traceability questions:
- Which tax treatment applies in this invoice set?
- Which control failed in this reporting workflow?
- Which clause in this policy governs document retention?
- Which field in this XML export maps to the downstream compliance output?
If the retrieval layer cannot surface the right chunk with the right surrounding metadata, the model is forced to improvise. That is where hallucination risk becomes a document-engineering problem rather than a prompt-engineering problem.
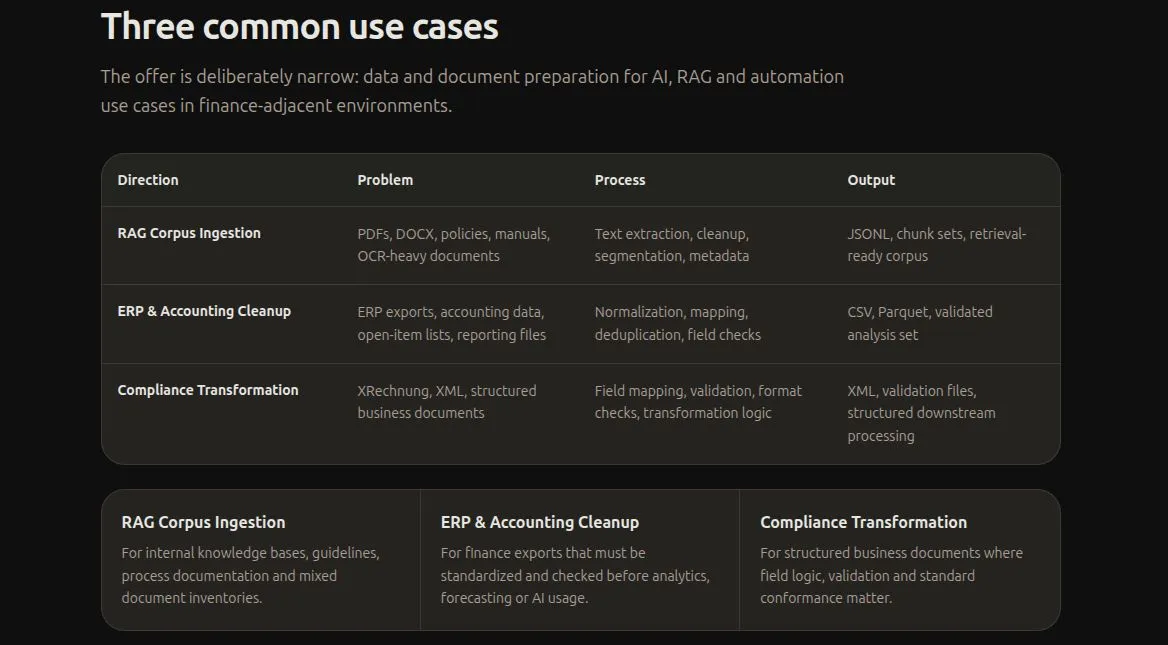
Document AI Is Structured ETL for PDFs
A lot of Document AI messaging still softens the problem too much.
The job is not “reading documents.” The job is turning unstable, layout-heavy, often OCR-noisy business files into structured outputs that can survive downstream use. In that sense, Document AI is closer to structured ETL than to a generic chat interface.
The hard part is not only extraction. It is the chain after extraction:
- Detect the relevant layout regions
- Recover text and table structure
- Extract entities and fields
- Normalize naming and formats
- Validate arithmetic, typing, and required fields
- Map outputs into a stable downstream schema
- Keep the transformation traceable
This is exactly how Google describes the category at a high level: Document AI transforms unstructured document content into structured data. That wording matters because it points to the real unit of value. The value is not “the model read the PDF.” The value is “the pipeline produced structured data that another finance or compliance workflow can actually use.” Google Document AI
That is why invoices, contracts, ESG reports, reporting packages, and mixed PDF inventories remain difficult. They are rarely pure text problems. They are structure problems, validation problems, and mapping problems.
Finance Raises the Standard for AI-Ready Systems
Every industry benefits from cleaner data. Finance depends on it in a more explicit and less forgiving way.
The target state is not just “a useful answer.” It is a useful answer that can be checked, explained, reconciled, and defended. That changes what AI-ready must mean in practice.
In a regulated or audit-sensitive workflow, it is not enough that a system can usually retrieve the right paragraph or often extract the right invoice fields. The pipeline must also support reproducibility, visible validation logic, and a review path for exceptions. That is why data controls remain central in banking-focused work on AI. McKinsey’s writing on banking data controls and generative AI adoption repeatedly returns to the same theme: data quality becomes more important, not less, once AI systems rely on large and often unstructured datasets. McKinsey on banking data controls McKinsey on gen AI in banking
If a team cannot answer where a result came from, which source document shaped it, which transformation rules were applied, and where human review entered the process, then the system may still be useful as an assistant. It is not yet ready for finance-critical use.
What AI-Ready Does Not Mean
This distinction matters because the phrase is easy to misuse.
AI-ready does not mean:
- the documents are searchable
- OCR text exists somewhere in a database
- a parser can return JSON
- the model can answer fluently about the source material
- a pilot works on a hand-cleaned demo corpus
Those things may be necessary. They are not sufficient.
A corpus can be searchable and still fail on attribution. A parser can return JSON and still fail on field consistency. A fluent answer can still be untraceable. In finance, those gaps are not cosmetic. They are exactly where trust breaks.
XRechnung Shows What Good Structure Looks Like
European e-invoicing is useful because it makes the discussion unusually concrete.
EN 16931 and its German implementation through XRechnung do not treat invoices as visual artifacts that an AI should somehow interpret later. They define a semantic model first. The invoice becomes structured data, with validation logic attached. Official federal guidance on e-invoicing in Germany is explicit about this machine-processable framing, and the XRechnung ecosystem itself is built around structured XML plus validation rules. E-Rechnung Bund KoSIT XRechnung
That is the contrast worth paying attention to.
A free-form PDF invoice may be human-readable, but it leaves downstream systems to infer structure after the fact. XRechnung starts from explicit fields, controlled semantics, and machine-checkable rules. Under GoBD-style thinking, that aligns naturally with the requirements for traceability and verifiability in digital bookkeeping processes. BMF GoBD
This does not mean XRechnung solves everything. Standards evolve, implementations still create friction, and real-world data still needs validation discipline. But it does provide a strong example of what “AI-ready by construction” can look like in finance.
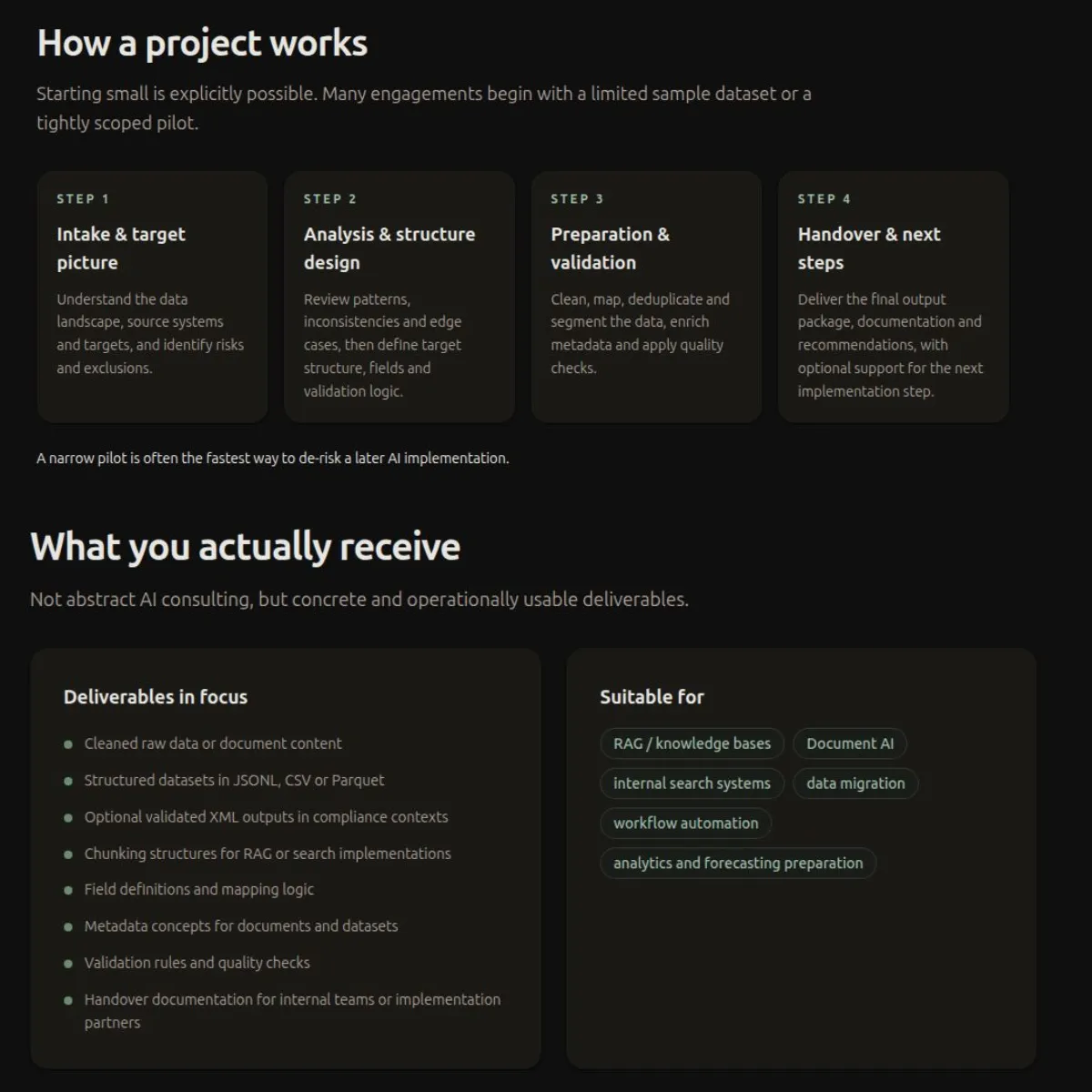
A Practical Standard for AI-Ready Finance Data
For finance workflows, a workable standard is this:
Data is AI-ready when it can be retrieved, transformed, validated, and explained in a way that remains operationally useful and auditable.
That becomes concrete through a short checklist.
At minimum, AI-ready finance data should have:
- stable structure at the field or chunk level
- metadata that preserves source, document type, section context, and business identifiers
- validation rules for required fields, typing, arithmetic, and format constraints
- documented transformation logic from source file to downstream output
- enough lineage to reconstruct how an answer, extraction, or result was produced
- a review path for low-confidence cases and exceptions
This is a higher bar than “machine-readable.” It is intentionally closer to “operationally defensible.”
Final Note
The more I work around finance and AI, the less I believe in model-first narratives.
A strong model can accelerate a good workflow. It can also expose a weak one very quickly. If the source layer is unstable, retrieval will be unstable. If the document structure is weak, extraction will be weak. If lineage is missing, trust will be weak. And if trust is weak, the workflow stays trapped in manual verification even when the demo looks impressive.
That is why “AI-ready finance data” is not a slogan I use casually.
It is the difference between a pilot that looks intelligent and a system that can actually be used.
If this is the layer your team is struggling with, the corresponding service direction is here:
AI Data Preparation for Finance Workflows
References
- BIS FSI Insight 73: In data we trust? Emerging policy and supervisory approaches to AI-related data usage
- EBA Final Report on Big Data and Advanced Analytics
- McKinsey: Capturing the full value of generative AI in banking
- McKinsey: Optimizing data controls in banking
- Microsoft Learn: Chunk large documents for vector search solutions in Azure AI Search
- Microsoft Learn: Chunk and vectorize by document layout or structure
- Anthropic: Introducing Contextual Retrieval
- Google Cloud Document AI documentation
- BMF GoBD guidance
- E-Rechnung in der Bundesverwaltung: E-invoicing for software companies and developers
- KoSIT XRechnung standard documentation